De flesta C-uppsatser inom sjuksköterskeutbildningen utgörs av en litteraturöversikt – det vill säga att studenterna väljer ett ämne, söker reda på relevant vetenskaplig litteratur i databaser som PubMed och CINAHL och syntetiserar den på något sätt.
Som allt annat vetenskapligt arbete kännetecknas ett examensarbete av ett systematiskt arbetssätt. Samtidigt finns en inbyggd begränsning i uppsatsarbetet – det får inte svälla ut och bli hur stort som helst, och därför måste det avgränsas på något vis. Viktigast här är att ha ett väl preciserat syfte som inte täcker in enorma mängder litteratur.
Vad är problemet?
Tyvärr är många uppsatser inte särskilt systematiska i sina litteratursökningar. Målet med en litteraturöversikt är att identifiera all relevant litteratur inom området och då blir sökfrågan man matar in i databasen avgörande. Men ofta kombineras termerna mer eller mindre godtyckligt, och risken är därmed stor att det är ett slumpartat snarare än systematiskt urval.
En uppsats om patienters upplevelser av kronisk smärta använde t.ex. följande sökstrategi (med vissa begränsningar på årtal m.m.):
| Databas |
Sökord |
Träffar |
| PubMed |
chronic pain AND caring |
44
|
|
chronic pain AND experience |
173
|
| CINAHL |
chronic pain (som överordnat ämnesord, dvs artikelns huvudämne) AND life experiences (som ämnesord) |
23
|
|
chronic pain AND patient perspective AND experience |
20
|
På vilket sätt är nu ovanstående sökning inkonsekvent? Jo, i fritextsökningarna används caring inte i CINAHL och patient perspective används inte i PubMed. Ingen sökning med MeSH-termer gjordes i PubMed. Och varför används förresten caring? Identifierar det så specifikt artiklar om patienters upplevelse? Och varför använder man i så fall inte också den närliggande, vanligare termen nursing?
Min slutsats är alltså att sökningen inte varit systematisk utan haft ett visst mått av godtycklighet. Man kan inte förvänta sig likartade resultat från de respektive databaserna från ovanstående sökning.
En anledning till detta kan som sagt vara att man inte rymmer hur många artiklar som helst inom ett examensarbete i omvårdnad. Men i stället för att göra några godtyckliga sökningar som resulterar i lagom många artiklar, är det rimligare att avgränsa på utgivningsår. Då får man en fullständig täckning av de senaste årens forskning i stället för ett godtyckligt urval av artiklar.
Hur kan man i stället göra?
Så hur bör man utforma sin sökstrategi? Jo, genom att göra sökningen i flera steg i stället och utnyttja att databaserna kan kombinera tidigare sökningar. Som exempel tar jag en litteratursökning jag gjorde under mitt avhandlingsarbete. Målet med sökningen var att identifiera litteratur som beskrev föräldrars erfarenheter av information om sitt barns cancersjukdom.
1. Identifiera de centrala koncepten
Vad vill jag veta? I exemplet ovan är de centrala koncepten föräldrar, information, barn, cancer.
Det innebär alltså att min sökning ska handla om föräldrar OCH information OCH barn OCH cancer. Jag vill inte ha artiklar som enbart handlar om föräldrar och information, och inte heller om information och cancer. Alla fyra koncepten måste vara med.
2. Identifiera synonymer för varje grupp av koncept
För att få hög recall, alltså så många relevanta träffar som möjligt, måste man identifiera tänkbara synonymer för varje koncept. Här har man stor hjälp av att se vilka ord som förekommer i titel eller abstract på artiklar man redan hittat och som man tycker är mitt i prick.
För konceptet information var mina synonymer educat*, informat*, teach*, knowled*, communica*, councel*.
Inom varje koncept kombineras synonymerna med ELLER – jag vill alltså ha någon av de orden. Och på samma sätt tog jag fram synonymer för de andra koncepten.
3. Mappa synonymerna till ämnesord
Olika databaser har olika ämnesordssystem. MeSH används i PubMed, och CINAHL har en egen uppsättning ämnesord som skiljer sig från MeSH. För varje databas får man alltså identifiera de ämnesord som beskriver respektive koncept.
I PubMed använde jag följande MeSH-termer för konceptet information: Health education, Information Seeking Behavior, Teaching Materials, Access to information, Information Literacy, Health Communication, Disclosure, Psychotherapy, Professional-Patient Relations, Professional-Family Relations, Self-Help Groups, Social Support, Counseling, Needs Assessment, Communication.
Även dessa kombineras med ELLER. En ganska lång radda, som du ser. Självklart behövs knappast så många i en C-uppsats. Och även här gjorde jag på samma sätt för de andra koncepten.
4. Sök koncepten separat
Nu börjar det roliga! (Hur man exakt går till väga skiljer sig mellan olika plattformar, så jag visar inte så exakt, men man får en aning i bilden längre ned.)
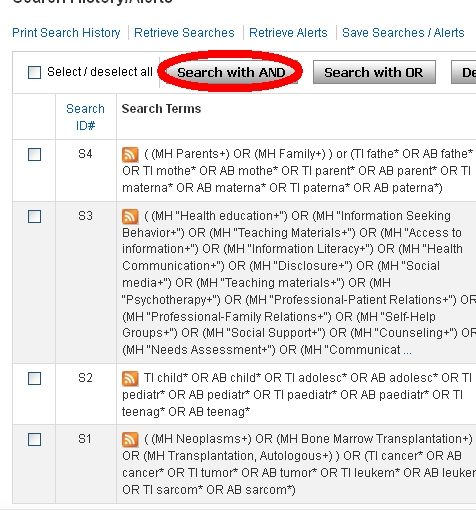
Man matar in sina söktermer, koncept för koncept, i sökmotorn. Orden och ämnesorden i varje koncept kombineras med operatorn OR, alltså ELLER. Vi vill ha antingen Neoplasms, Bone Marrow Transplantation osv. Så här blev i alla fall resultatet i Medline:
| Koncept |
Sökord |
Antal träffar |
| Cancer |
MeSH-termer:
Neoplasms
Bone Marrow Transplantation
Transplantation, Autologous
Titel och abstract:
cancer*
tumor*
leukem*
sarcom* |
2 754 140
|
| Barn |
Titel och abstract:
child*
adolesc*
pediatr*
paediatr*
teenag*
(Här fanns inga lämpliga MeSH-termer.) |
1 039 475
|
| Föräldrar |
MeSH-termer:
Parents
Family
Titel och abstract:
fathe*
mothe*
parent*
materna*
paterna* |
603 337
|
| Information |
MeSH-termer:
Health education
Information Seeking Behavior
Teaching Materials
Access to information
Information Literacy
Health Communication
Disclosure
Social media
Teaching materials
Psychotherapy
Professional-Patient Relations
Professional-Family Relations
Self-Help Groups
Social Support
Counseling
Needs Assessment
Communication
Titel och abstract:
educat*
informat*
teach*
knowled*
communica*
counsel* |
1 499 156
|
5. Kombinera sökningarna
Nu har vi fyra enorma sökmängder. Det ser ut ungefär så här:

Och här vill vi förstås komma åt det mörkaste området i mitten, där alla söktermerna finns med. Alltså föräldrar OCH barn OCH cancer OCH information.
I databasen måste vi alltså kombinera de fyra olika sökmängderna med varandra. Enklast visar man sökhistoriken, kryssa för de fyra koncepten och kombinerar dem med AND. I EBSCO:s gränssnitt för Medline ser det ut ungefär så här:
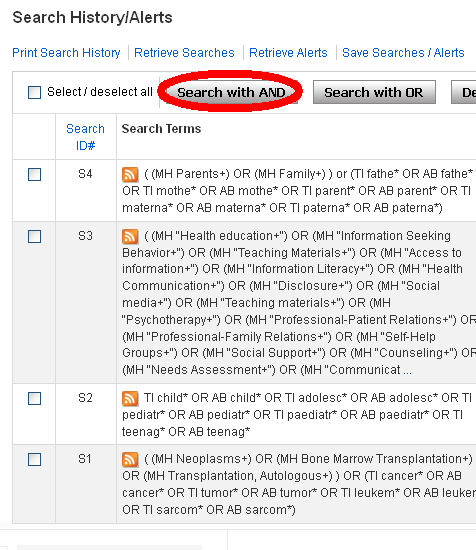
Man kryssar alltså för alla de sökmängder man vill ha med och klickar i Search with AND.
Till sist blev det 2 573 träffar. Det är fortfarande en enorm sökmängd, men för en välavgränsad C-uppsats bör det bli betydligt färre.
Slutord
Ungefär såhär går reviewproffsen till väga när de gör en systematisk litteratursökning. Titta t.ex. på det här exemplet från brittiska Centre for Reviews and Disseminations. Eller se ett exempel från Cochrane (bläddra till sidan 189)!
Självklart måste man ändå experimentera sig fram och prova några olika strategier, men det här är betydligt mer systematiskt än det mer godtyckliga sökandet vi började med.
Jag inser att en C-uppsats inte kan jämställas med en Cochranereview, men jag ser ändå ett värde i att arbeta mer systematiskt än vad man gör nu. Självklart måste man begränsa antalet artiklar studenterna ska analysera, men då hävdar jag att en kronologisk avgränsning mer rimlig än en godtycklig sökning från första början.
Visningar: 1398